exp

Experiment design, deployment, and optimization
Optimizing model hyperparameters is an ubiquitous task in Machine Learning research. Finding baselines that are useful as a ground truth for ablation studies implies that you want the comparison to be as fair as possible: we want to compare the best possible models for the given architectures. In the case of neural network models, this can mean adjusting learning rate, regularization weights, dropout probabilities, etc. Doing ablation studies for large models (or large datasets) can be particularly expensive, not just in terms of time, but (for GPU-accelerated models) of energy as well.
Writing code to run the experiments, take advantage of multiprocessing, or distributing model runs through different GPUs can be a pain. EXP separates model specification from model configuration, experiment deployment and result logging.
EXP is a tool / library for experiment design, model deployment, and hyperparameter optimization that performs 2 basic tasks:
-
model execution from parameter specifications;
-
model optimization given a parameter space.
Model Search with Bayesian Optimization
EXP wraps around scikit-optimize to find the best configuration for a model using global Bayesian optimization. For a tutorial on Bayesian Optimization see 1807.02811:
python -m exp.gopt -p basic.conf -m runnable.py -n 20 --workers 4
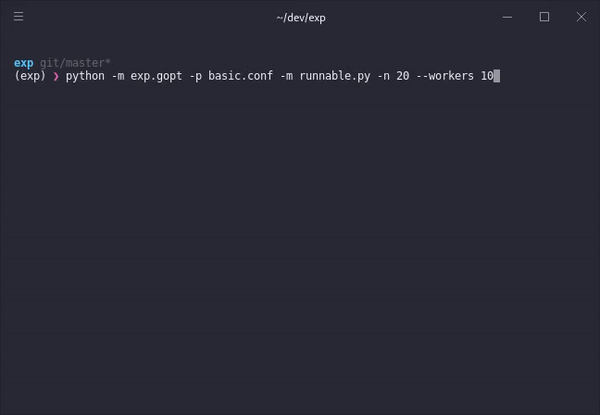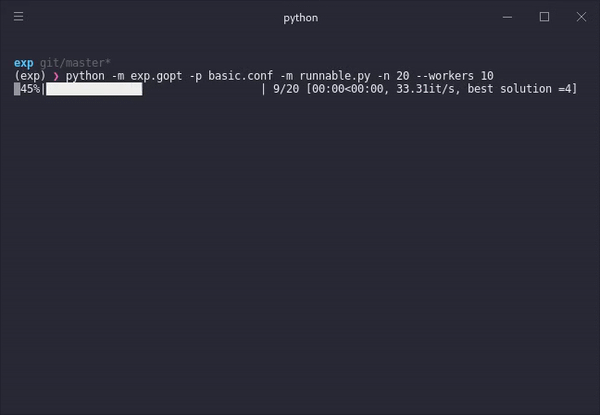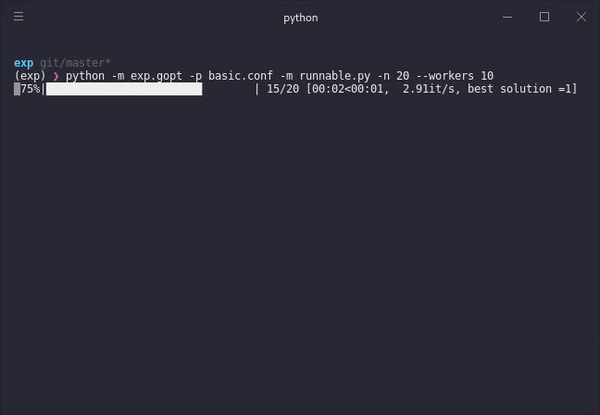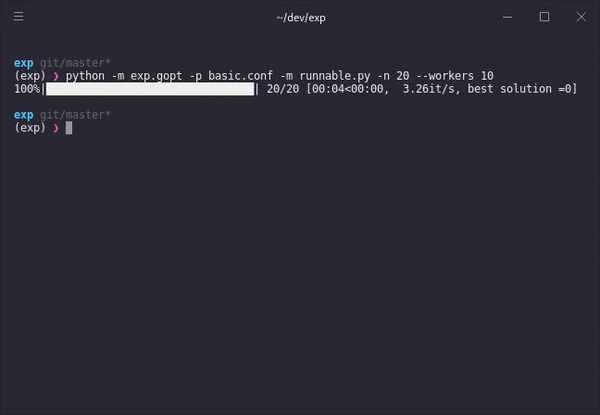
Step-by-step
With a single command, we can take any model and a parameter space specified in a configuration file and the optimization procedure will try to find the best possible model iteratively. Each model run informs the model about possible configuration candidates that might lead to better performance.
Suppose you want to optimize a simple function, say x², you want to find the parameter that minimizes this function, a parameter space file written in TOML might look like this:
[x]
type = "random"
bounds = [-10,10]
dtype = "int"
prior = "uniform"
The only thing you need now is a runnable model. A model here is just a python
file runnable.py with a run function that takes a parameter dictionary as
input:
def run(x=1, **kwargs):
return x ** 2
Running the previous command with these two files will evaluate a number of initially random configurations in parallel (one for each available worker), generate a bayesian model of how the performance function might react to different configurations. The optimizer then suggests new configurations within the defined parameter value bounds. This continues iteratively until a number of specified runs n has passed.
Additionally, a gpu flag can be added to restrict the number of workers to the
number of available GPU units in a machine. Each worker will only have access to
1 gpu unit (in this case using the CUDA_VISIBLE_DEVICES variable). This allows
for a safe deployment of models using frameworks like TensorFlow or PyTorch that
use every single GPU unit available to run their computational graphs.
Some caveats
The larger the parameter space, the harder the optimization problem, so this is not a silver bullet. I use Bayesian Optimization to complement my intuition about what parameters might yield a good model.
Gaussian optimization assumes that the parameter values are continuous, the optimizer does take care of corner cases, like integer or categorical values, but I recommend reading on the subject if you need to optimize discrete parameters, a better alternative for neural network architecture search might be the use of evolutionary computation techniques, but these are not yet available in the tool.
Thank You
For more documentation check out the project on Github. If you have any questions, drop me a line on twitter, or leave a comment bellow.